在做的项目使用mongodb作为主数据库,期间app需要实现设计网站的功能(核心是
关注、信息流),本文为期间找到的比较好的mongodb官方博客文章,部分翻译并加上自己的理解与大家分享。
如果想用mongodb作为微博或者Facebook之类的社交网站的数据库,它的主要优势在于更容易处理大数据,更容易分布式存储,下文将探讨开发社交网站中mongodb数据建模(schema设计)的方式以及其优缺点。在开始设计之前,必须明确如下几点社交网络的特点: - 未来该网站可能会有海量的数据,且时刻都有大量的读写操作 - 用户的读写操作并不均匀,明星用户有上万的粉丝则数据的写操作非常大,普通用户粉丝少但关注者多则读的操作多。 - 该社交网站需能快速响应用户的请求 - 粉丝得到的信息不是一次性的,作者对该信息的操作(删除,更新等)粉丝都能得到
使用mongodb的文档集分布存储将能保证海量数据有效的读写操作,基于该技术方案的Schema设计有如下三种: - 读时整合信息流(即粉丝获取微博大V的微博或获取Facebook的好友状态) - 写时整合信息流 - 写时将信息流整合成块状 没有任何方案是完美的解决方案,以上三个方案有各自的利弊,必须根据网站的实际情况来选择。下文将信息发布者简称为作者,信息接收者简称为粉丝,所发布的信息简称为微博
读时整合信息流
当作者发布新微博或者有新的动态时,生成的微薄将包含它的所有接收者即作者的所有粉丝,分布存储时只能按照作者来分布,因为接收者字段是一个数组
db.shardCollection( "dbname.activity", {author: 1})
db.activity.ensureIndex( {to: 1, date: 1})
//保存一条新微博
activity = {
author: "Eisneim"
to: ["Terry", "Jane"], // 所有粉丝
date: new Date(),
type:"publish",
content: "一条新微博的内容",
.....
}
db.inbox.save (activity)
//粉丝显示最新的微薄
db.activity.find ({ to: "Terry"}).sort({date:-1})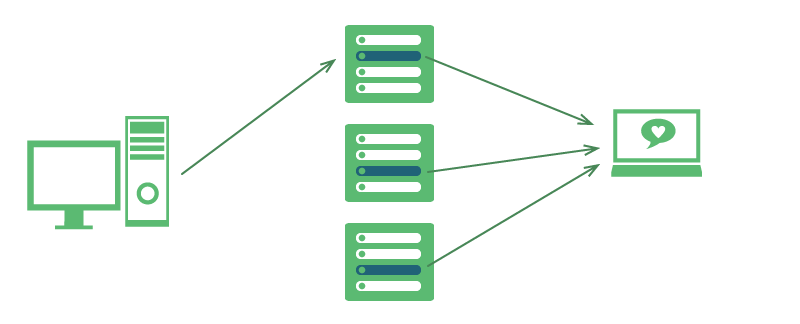
该方案将分布存储activity文档集合,将作者相同的微博放在同一台服务器上,所以在发布的时候非常快,但是当它的粉丝在读取微博的时候将会比较慢,因为粉丝关注了很多作者,他应该看到的微博分布在不同的服务器上,当他发出查看请求时,控制服务器将向子服务器发出指令并获取在to字段包含该粉丝ID的微博,子服务器再将找到的微博返回给控制服务器,如果某个服务器出现了延迟,控制服务器也必须等待,服务器间的通信的通信过程也远慢于从硬盘里读出数据,况且为了完成一个查询每台服务器都要运作起来,一旦用户数量大了,每台子服务器的压力都很大。
读时整合信息流的特点是:写非常快,读慢,适合大量发送信息而很少阅读信息的“反社交”应用
写时整合信息流
这种方式的做法是当作者有新微博或者动态时,为每一个粉丝都生成一条微博,也就是说如果一个作者有100万的粉丝,那么他发一条微博,服务器将保持100万条内容同样而接收者不同的微博。这种方案听起来似乎不可思议,但是不要低估了目前存储技术的发展速度。分布存储的方式是按照owner来分的,也就是一个粉丝应该看到的微博都在同一台服务器上。
db.shardCollection( "dbname.activity", {owner: 1})
db.activity.ensureIndex( {owner: 1, date: 1})
//保存一条新微博
var fans = ["Terry", "Jane"];
fans.forEach(function(owner){
activity = {
owner: owner
author: "Eisneim"
date: new Date(),
type:"publish",
content: "一条新微博的内容",
.....
}
// 异步执行
db.inbox.save (activity)
})
//粉丝显示最新的微博
db.activity.find ({ owner: "Terry"}).sort({date:-1})
相对于“读时整合信息流”,写时整合信息流在作者发布的新的微博的时候利用nodejs的异步执行的特点,毫无延迟感,但服务器的压力肯定是有的,尤其是那些粉丝上百万的作者在发布新微博时。这种方式相对于第一种方式会产生跟多重复的数据,这点可能是最值得担心的问题。这种方式最大的优点是读取非常快,因为一个粉丝所应该看到的微博都在同一台服务器,无需等待通信过程,由于社交网站中读远大于写,看微博的人远大于发微博的人,所以这种方式比第一种方式更时候社交网站。
写时整合信息流的特点是:写慢,读快,适合常规社交网站
写时将信息流整合成块状
该方案类似于第二种方案“写时整合信息流”,区别是将粉丝的所有微博按一定数量分块存储,例如每50条放在一个数组里面。
db.shardCollection( "dbname.activity", {owner: 1,sequence:1})
db.activity.ensureIndex( {owner: 1, date: 1})
UserSchema = new Schema({
// _id 自动生成
username:String,
activityCount:Number,
.....
});
ActvitySchema = new Schema({
sequence:Number,
owner:{type:Schema.Types.ObjectId, ref: 'User'},
activities:[{
author:{type:Schema.Types.ObjectId, ref: 'User'},
......
}]
});在每次作者发布新微博时,将微博放入粉丝的“信息块”中,同时所有粉丝的activityCount递增。
// 作者发布新微博
var fans = ["Terry", "Jane"];
var activity = {
微博内容
.......
}
fans.forEach(function(owner){
User.findOneAndUpdate({_id:owner},
{"$inc":{"activityCount":1}},
{upsert: true},
function(err,user){
var count = user.activityCount
var sequence = Math.floor(count/50);
// 将新微博插入块中
Activity.update({owner:owner,sequence: sequence},
{
$push:{ activities: activity }
},
{upsert:true} );
});
})
// 粉丝读取微博
Activity.find({owner:userId,sequence:sequenceNumber}).sort({sequence:-1})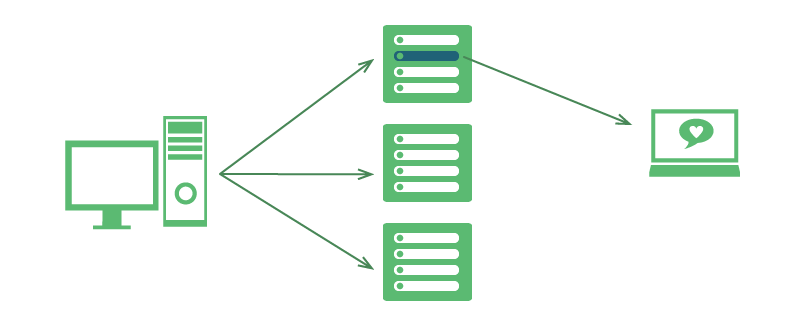
获得50条微博只需要2次数据库读取,而在第二种方案则需要50次以上的数据库读取,效率差异是明显的。但是在保存微博的适合,不仅要保存微博本身,还要更新User对象,如果粉丝上万,则两次数据库操作都要执行上万次,因此在写操作时,本方案比第二方案也更慢。
写时将信息流整合成块状的特点是:写非常慢,读非常快,扩大了第二种方案与第一种方案的差异。
由于openwear并非百分之百社交网站,且第三种方案并不灵活不能记录太复杂的activity信息而openwear的activity信息类型不只一种,比如当某作者关注了第三个用户,粉丝也能看到被关注的人的信息。所以选择第二种方案“写时整合信息流”更为合适。
var ActivitySchema = new Schema({
type:String,// 类型pulish,comment,follow,rate,
owner:{type:Schema.Types.ObjectId,ref: 'User'},
// 是哪一位作者产生的动态信息
following:[{type:Schema.Types.ObjectId,ref: 'User'}],
// 如果是关注用户, 第三个用户的ID
targetUser:{type:Schema.Types.ObjectId,ref: 'User'},
// 如果是pulish,comment,rate时,记录下它的ID
item:{type:Schema.Types.ObjectId,ref: 'Clothing'},
// 如果是评论,记录评论内容,这里是数组,便于记录多个作者评论同一个post
comment:[String],
});